





Machine learning is at the core of the technological revolution reshaping industries across the globe. Whether you’re a data scientist, a business analyst, or an enthusiast diving into the world of artificial intelligence, understanding machine learning algorithms is crucial. In this article, we will explore the various types of machine learning algorithms, their applications, and how they transform data into actionable insights.
What Are Machine Learning Algorithms?
Machine learning algorithms are the building blocks of AI systems that enable computers to learn from data, identify patterns, and make decisions with minimal human intervention. These algorithms process vast amounts of data to predict outcomes, classify information, and even make complex decisions based on prior knowledge. The core principle behind these algorithms is their ability to improve over time as they are exposed to more data, making them highly valuable for tasks that require precision and adaptability.
Types of Machine Learning Algorithms
Machine learning algorithms are categorized into three primary types: supervised learning, unsupervised learning, and reinforcement learning. Each type has distinct characteristics and is suited for specific tasks.
1. Supervised Learning Algorithms
Supervised learning algorithms are among the most widely used in machine learning. In this approach, the algorithm is trained on a labeled dataset, which means the input data is paired with the correct output. The algorithm learns to map inputs to the correct outputs and can predict the outcome of new, unseen data.
Popular Supervised Learning Algorithms:
-
K-Nearest Neighbors (KNN): KNN is a simple, non-parametric algorithm used for classification and regression tasks. It works by finding the 'k' closest data points in the training set to a new data point and predicting the output based on the majority class (for classification) or the average (for regression) of those neighbors.
-
Support Vector Machines (SVM): SVM is a powerful classification algorithm that works by finding the hyperplane that best separates different classes in the feature space. It is especially effective in high-dimensional spaces and cases where the number of features exceeds the number of samples.
-
Decision Trees: Decision trees are hierarchical models that split the data based on feature values, leading to a tree-like structure of decisions. Each node represents a decision based on a feature, and each branch represents the outcome of that decision. They are easy to interpret and visualize.
-
Random Forest: A Random Forest is an ensemble learning method that combines multiple decision trees to improve classification accuracy. By averaging the results of several trees, it reduces the risk of overfitting and increases the model's robustness.
2. Unsupervised Learning Algorithms
Unsupervised learning algorithms are used when the data does not have labeled outputs. Instead of predicting a target variable, these algorithms identify patterns and structures within the data. This approach is ideal for exploratory data analysis, where the goal is to uncover hidden patterns.
Popular Unsupervised Learning Algorithms:
-
K-Means Clustering: K-Means is a clustering algorithm that partitions data into 'k' clusters based on similarity. The algorithm assigns each data point to the nearest cluster center, which is iteratively refined until convergence. K-Means is widely used in market segmentation, image compression, and anomaly detection.
-
Principal Component Analysis (PCA): PCA is a dimensionality reduction technique that transforms the data into a new set of uncorrelated variables called principal components. These components capture the maximum variance in the data, making PCA useful for reducing the complexity of large datasets while preserving important information.
-
Hierarchical Clustering: Unlike K-Means, hierarchical clustering creates a tree-like structure of clusters. It can be agglomerative (bottom-up) or divisive (top-down). This method is useful for data where the number of clusters is not known in advance, and a hierarchy of clusters is desired.
3. Reinforcement Learning Algorithms
Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent takes actions that maximize cumulative rewards over time. Unlike supervised learning, reinforcement learning does not rely on labeled input/output pairs but learns from the consequences of its actions.
Popular Reinforcement Learning Algorithms:
-
Q-Learning: Q-Learning is a model-free reinforcement learning algorithm that seeks to learn the value of an action in a particular state. It uses a Q-table to store the values and updates them based on the agent’s experiences. Q-Learning is used in applications like robotics, game playing, and navigation.
-
Deep Q-Networks (DQN): DQN is an extension of Q-Learning that uses deep neural networks to approximate the Q-values. This allows the algorithm to handle high-dimensional state spaces, making it suitable for complex tasks such as video game playing and autonomous driving.
-
Monte Carlo Methods: Monte Carlo methods are a class of algorithms that rely on repeated random sampling to estimate the properties of a system. In reinforcement learning, Monte Carlo methods are used to evaluate and improve the policy based on the average return from multiple simulations.
Real-World Applications of Machine Learning Algorithms
Machine learning algorithms are transforming various industries by enabling smarter decision-making and automation. Here are some real-world applications across different sectors:
1. Healthcare
In healthcare, machine learning algorithms are used for predictive modeling, diagnostics, and personalized treatment plans. For example, neural networks are employed to analyze medical images for early detection of diseases like cancer. Supervised learning algorithms like Random Forest are used to predict patient outcomes and optimize treatment protocols.
2. Finance
In the finance industry, algorithms such as SVM and Decision Trees are used for credit scoring, fraud detection, and algorithmic trading. Machine learning models can analyze vast amounts of financial data to identify patterns, make predictions, and automate trading decisions, significantly improving efficiency and reducing risk.
3. Technology
Technology companies leverage machine learning for a wide range of applications, from natural language processing (NLP) to image recognition and recommendation systems. For instance, recommendation algorithms powered by KNN and neural networks are used by platforms like Netflix and Amazon to suggest movies and products to users based on their preferences.
4. Retail
Retailers use machine learning to enhance customer experiences through personalized marketing, demand forecasting, and inventory management. Clustering algorithms like K-Means help segment customers based on purchasing behavior, enabling targeted marketing campaigns that increase sales and customer loyalty.
5. Autonomous Vehicles
Reinforcement learning algorithms are at the heart of autonomous vehicle technology. These algorithms enable vehicles to navigate complex environments, make real-time decisions, and continuously learn from their experiences to improve safety and efficiency.
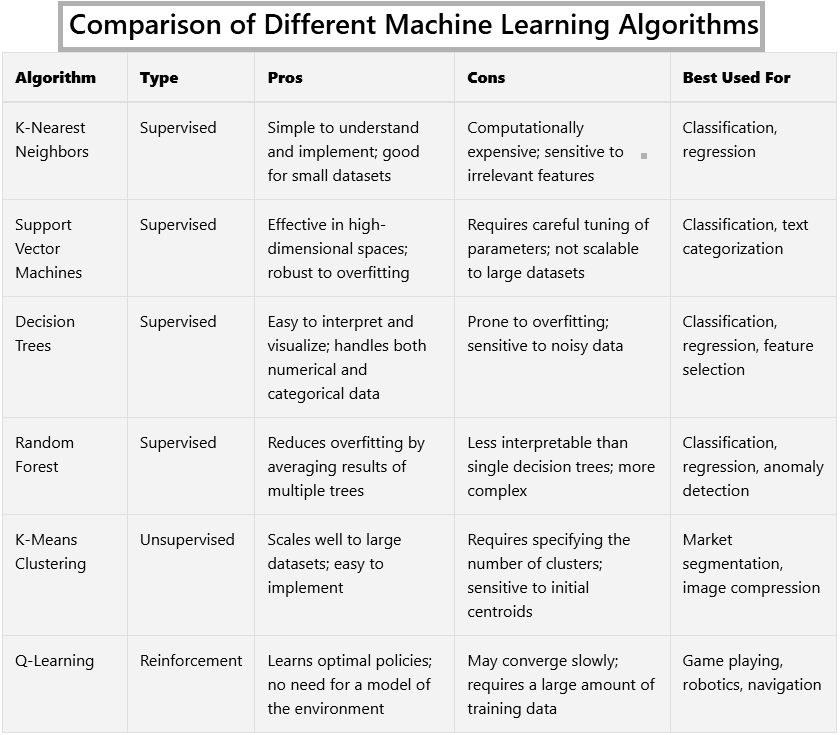
Comparison of Different Machine Learning Algorithms
Choosing the right machine learning algorithm depends on various factors, including the nature of the data, the problem at hand, and the desired outcome. Below is a comparison of some of the key algorithms:
| Algorithm | Type | Pros | Cons | Best Used For |
|---|---|---|---|---|
| K-Nearest Neighbors | Supervised | Simple to understand and implement; good for small datasets | Computationally expensive; sensitive to irrelevant features | Classification, regression |
| Support Vector Machines | Supervised | Effective in high-dimensional spaces; robust to overfitting | Requires careful tuning of parameters; not scalable to large datasets | Classification, text categorization |
| Decision Trees | Supervised | Easy to interpret and visualize; handles both numerical and categorical data | Prone to overfitting; sensitive to noisy data | Classification, regression, feature selection |
| Random Forest | Supervised | Reduces overfitting by averaging results of multiple trees | Less interpretable than single decision trees; more complex | Classification, regression, anomaly detection |
| K-Means Clustering | Unsupervised | Scales well to large datasets; easy to implement | Requires specifying the number of clusters; sensitive to initial centroids | Market segmentation, image compression |
| Q-Learning | Reinforcement | Learns optimal policies; no need for a model of the environment | May converge slowly; requires a large amount of training data | Game playing, robotics, navigation |
Conclusion
Machine learning algorithms are indispensable tools that are revolutionizing how we process data, make decisions, and automate tasks. From supervised learning techniques like KNN and Decision Trees to unsupervised approaches like K-Means Clustering, each algorithm offers unique strengths that make it suitable for specific applications. Understanding these algorithms, their types, and their applications can empower data scientists, software developers, and business analysts to harness the full potential of machine learning in their respective fields.
As technology continues to evolve, staying informed about the latest developments in machine learning will be crucial for anyone looking to remain competitive in today’s data-driven world.
Artificial intelligence (AI)